Наследование
Перед тем, как рассматривать другой тип полиморфизма на конкретных примерах, необходимо чуть более подробно поговорить о некоторых особенностях системы типов в С++. Эти особенности – подтипы и шаблоны – вводят в оборот новые инструменты, которые позволяют использовать полиморфные типы данных. А именно, полиморфные типы данных позволяют создавать универсально полиморфные функции – такие функции, которые могут работать с бесконечным количеством уникальных типов. Очевидно, что такого эффекта нельзя добиться перегрузкой или приведением типов, потому что физически невозможно создать бесконечно много перегруженных версий той или иной функции, так же физически невозможно описать бесконечно большой список правил приведения того или иного типа в другой. Здесь на помощь приходит полиморфизм подтипов.
Основной механизм для достижения такой полиморфности – наследование – в разных языках реализуется по-разному. Суть наследования состоит в расширении свойств и методов отдельно взятого типа данных за счет создания нового, “дочернего” типа данных, базирующегося на существующем типе. То есть, новая структура перенимает все поля другой структуры без необходимости их копировать руками. Компилятор рассматривает новый тип как принадлежащий к иерархии базового типа. Таким образом возникает ситуация, в которой любой объект базового типа можно легко заменить объектом нового подтипа без каких-либо ошибок. Это работает благодаря тому, что все поля базового типа в новом подтипе тоже присутствуют, соответственно те инструкции программы, которые обращаются к таким полям, найдут их и в новом подтипе гарантированно.
По этой причине иерархии наследования принято изображать в виде древовидной структуры, в которой базовая структура играет роль корня дерева. Например, на иллюстрации ниже показана иерархия чисел, которая взята как фрагмент системы типов языка Smalltalk.
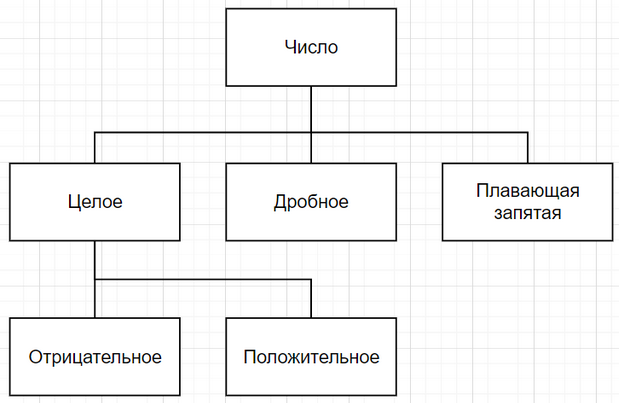
Как говорилось чуть выше, основное предназначение классов, которые составляют систему типов, представленную на диаграмме – управлять поведением своих объектов. Тогда становится очевидным, что целое число и дробное число ведут себя примерно одинаково, потому что им присущи одни и те же операции (взятие по модулю, сложение, вычитание и т.д.) – следовательно, они оба принадлежат классу чисел. Так же отрицательное целое число ведет себя схожим образом с любым другим целым числом, а если продолжить аналогию – с любым другим числом, поэтому отрицательные целые числа являются подтипом целых чисел, которые в свою очередь являются подтипом чисел. При всем при этом поведение подтипа становится чуть более специфичным по сравнению со своим базовым типом (“супер-типом”). Например, всем числам присущи операции сложения и вычитания, но только дробные числа имеют числитель и знаменатель и т.д.
Если рассматривать наследование как абстрактный механизм классификации, он выглядит понятно и местами элегантно. Реализация наследования – совсем другое дело. Например, в Smalltalk наследование реализуется через инициализирование объектов. Каждый класс в системе типов - это объект своего базового класса. Пользуясь иллюстрацией выше, “целое число” - это одновременно класс для “положительного числа” и объект класса “число”. Отсюда можно сделать вывод, что все классы - это объекты других классов, за исключением корня иерархии классов, потому что корень ничего не наследует и является чистым “абстрактным” классом. Благодаря этому “классы” можно изменять в ходе работы программы* (дополнять новыми методами или изменять существующие), так как в конечном итоге они ведут себя как переменные.
В C++ используется другой подход. Так как понятие “класса” тесно связано со структурами данных, делать подтипы в виде объектов своей базовой структуры не так удобно. Разработчики посчитали более рациональным обратный подход: сделать базовый “класс” объектом внутри своей дочерней структуры. По аналогии с иллюстрацией выше эта иерархия выглядит примерно так:
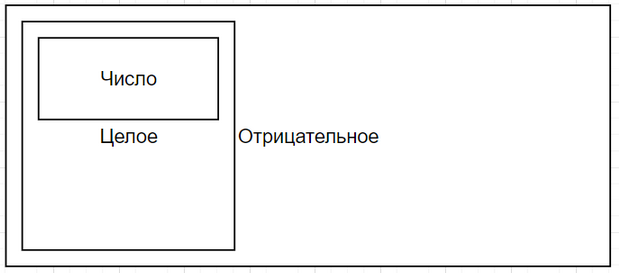
На такой диаграмме легче визуализировать принцип расширения одной структуры другой, так как подструктура включает в себя объект своей базовой структуры целиком.
struct number {};
struct integer : number
{
long long int x{0};
};
struct positive : integer
{
positive(long long int a)
{
this->x = (a < 0) ? -a : a;
}
};
Двоеточие после названия структуры ожидает справа от себя имя базовой структуры. Это является сигналом для компилятора: при инициализации объекта типа positive будет инициализирован и объект типа integer, а следовательно - и объект number. Все они будут включены один в другой по принципу матрешки (этот прием называется “композицией”). Получается, что мы имеем полное право написать следующий код:
positive i = -1;
assert(i.x == 1);
В нем сама структура positive не имеет поля x, но может получить доступ к соответствующему полю своей материнской структуры. Это отношение очевидно, если посмотреть на полное описание типа переменной x: long long integer::x – то есть, эта переменная изменяется в анонимном скрытом объекте типа integer, доступ к которому осуществляется через другую переменную типа positive.
Внимательным глазом можно заметить, что этот подход немного пересекается с тем, как наследование устроено в Smalltalk, классы тоже инициализируются как объекты (и это естественно, так как и С++, и Smalltalk, разрабатывались с оглядкой на другой язык – Simula-67**).
Упражнения
Возможно, не каждому из прочитавших эту часть было понятно по какой цепи выполнялся код, который привел к присваиванию значения “1” переменной, которая инициализировалась числом -1. Чтобы явно увидеть связь между всеми операциями, вызванными инструкцией positive i = -1; следует дополнить все определения структур number, integer и positive. Затем, используя дебаггер или текстовую трассировку***, подтвердить ход и конкретное место исполнения инструкций в программе. Для этого следует использовать конструкторы и их переопределение.
#include <stdio.h>
struct number {};
struct integer : number
{
integer(long long int a) : x(a)
{
printf("integer: %d\n", this->x);
}
long long int x{0};
};
struct positive : integer
{
positive(long long int a) : integer((a < 0) ? -a : a)
{
printf("positive: %d\n", this->x);
}
};
Новым для читателя может стать вызов конструктора суперструктуры (integer) в списке инициализации конструктора ее дочерней структуры (positive). Это необходимо сделать в случае использования списка инициализации потому, что структура positive не имеет поля под именем x, о чем компилятор нам бы и сказал (error: class 'positive' does not have any field named 'x'). Так как поле х принадлежит структуре integer, а вы уже знаете, что анонимный объект этого типа будет создан при инициализации переменной типа positive, этот анонимный объект должен быть инициализирован раньше, чем его дочерняя структура. Чтобы его инициализировать вручную надо указать какой именно конструктор использовать для этого. Компилятор сам разберется как эта инициализация происходит. Если теперь запросить программу выполнить инструкцию positive i = -1;, в окне вывода появятся две строки:
integer: 1
positive: 1
Из этого становится понятно, что сначала будет вызван конструктор integer, в качестве значения ему будет передано число 1 (так как сработает проверка (a < 0) ? -a : a), а затем уже вызовется конструктор positive. Если же, например, выполнить инструкцию integer i = -1;, сработает только конструктор integer. Он инициализирует поле x значением “-1”, и на этом все закончится.
Может возникнуть закономерный вопрос: зачем объявлять пустую структуру number, если она никакую работу не выполняет? Ответ на этот вопрос будет дан в следующей части.
Сноски
*Это верно относительно классов в языке Smalltalk и других похожих языках, но не распространяется на классы в языке С++.
***Code tracing - техника визуального подтверждения значения одной или нескольких переменных на каждом этапе работы программы, как правило выполняемая с помощью вывода значений в одно из “окон” программы, либо – вручную на бумаге.
Copyright © 2022 Брынзан, Л.В.
GNU General Public License
“Commons Clause” License Condition v1.0
GPL Attribution-ShareAlike 4.0 International